Data Manipulation(2021/3/8)
이번시간엔 파이썬관련해서 많은 꿀팁들이 있었다. 많은 팁중에서 굉장히 유용하거나 가장 인상깊었던 부분들을 작성했다.
몰랐던 부분 정리
Select_dtypes()
# Include data types
drinks.select_dtypes(include=['number', 'object', 'category', 'datetime'])
# Exclude data types
drinks.select_dtypes(exclude='number')항상 Boolean형태로 조건문을 맞추어서 특정 dtype을 끌어냈었던 것을 한줄로 끝낼 수 있는 간단하면서 효율적인 방법이다.
pd.concat과 list comprehension시에 유의사항
# Concatenate "before" transpose datasets
files = ['df1', 'df2', 'df3', 'df4', 'df5']
df_list = pd.cancat([pd.read_csv(file) for file in files])
def trans_data(df):
df = df.transpose()
new_header = df.iloc[0]
df = df[1:]
df.columns = new_header
return df[-1:]
# Concatenate "After" transpose datasets
def trans_data(df):
df = df.transpose()
new_header = df.iloc[0]
df = df[1:]
df.columns = new_header
return df[-1:]
df_list = [(pd.read_csv(file)) for file in files]
df = trans_data(pd.concat(df_list))에러발생
순서에 따라서도 결과값이 달라질 수 있다는 것을 명심하게 되었다. 초반에 후자의 방식을 사용하느라 1시간동안 애먹었지만 값진 삽질이였다.
Dictionary를 활용한 변환방식
- Convert multiple data types
# convert data types
df.astype({'column1':'float', 'column2':'int', 'column': category}).dtypes
- pd.style.format() 을 통한 다양한 시각화
format_dict = {'매출액':'${:.2f}', '자산총계':'${:.2f}', 'EPS(원)':'${:.2f}'}
(df.style.format(format_dict)
.hide_index()
.bar(['매출액'], color='lightblue', align='zero')
.background_gradient(subset='자산총계', cmap='Blues')
.highlight_min('EPS(원)', color='red')
.highlight_max('EPS(원)', color='lightgreen')
.set_caption('Kosdaq Index in 2020')
)
table을 시각화와 같이 보여줄 수 있다는 것에 굉장히 매력을 느꼈다. 더 찾아보고 탐험해봐야겠다.
reference: pandas.pydata.org/pandas-docs/stable/user_guide/style.html
Styling — pandas 1.2.3 documentation
You’ve seen a few methods for data-driven styling. Styler also provides a few other options for styles that don’t depend on the data. The best method to use depends on the context. Use the Styler constructor when building many styled DataFrames that sh
pandas.pydata.org
Threshold를 활용한 NA 다루는 법
# NA가 각 행의 10% 이상 차지할 경우 drop
df_chal.dropna(thresh=len(df_chal)*0.9, axis=1)Missing value를 다루는 방법은 다양하다는 것을 안다. 허나 threshold를 통해서 그 column을 drop할 수 있다는 사실은 정말 처음 알았고 나중에 유용할 수 있다는 생각에 적었다.
Data Split을 통한 feature engineering의 가능성
- str.split() 활용법

↓
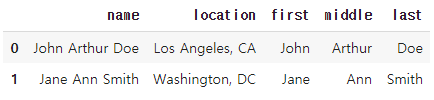
df[['first', 'middle', 'last']] = df.name.str.split(' ', expand=True)
- List형태의 데이터를 나누어 저장하기

↓

# Convert List to Series
df_new = df.col_two.apply(pd.Series)
# Concatenate new dataframe with the original
pd.concat([df, df_new], axis='columns')
오늘은 파이썬을 활용함에 있어서 굉장히 유용한 꿀팁들을 많이 얻어가는 시간들이였다. 작성한 것 외에도 많은 것들이 있지만 그중에서 가장 인상 깊고 감탄하면서 꼭 활용해야겠다는 부분들만 따로 추려 적용해 보았다. 특히, Style.foramt()과 Data Split부분은 두고두고 쓸 아주 유용한 내용이다.
Reference: github.com/justmarkham/pandas-videos/blob/master/top_25_pandas_tricks.ipynb
justmarkham/pandas-videos
Jupyter notebook and datasets from the pandas Q&A video series - justmarkham/pandas-videos
github.com
'[코드스테이츠] AI부트캠프2기 > Section 1' 카테고리의 다른 글
| [AI부트캠프 2기] - 6~7일차 (feat. 코드스테이츠) (0) | 2021.03.12 |
|---|---|
| [AI부트캠프 2기] - 5일차 (feat. 코드스테이츠) (0) | 2021.03.11 |
| [AI부트캠프 2기] - 4일차 (feat. 코드스테이츠) (0) | 2021.03.09 |
| [AI부트캠프 2기] - 2일차 (feat. 코드스테이츠) (0) | 2021.03.07 |
| [AI부트캠프 2기] - 1일차 (feat. 코드스테이츠) (0) | 2021.03.04 |



댓글